The big issue during any R and D effort is unlocking the full value from your experimental resources.
The Experimental Network Value (ENV) is a measure of how powered your R and D efforts are, and is a function of the number of experimentalists/scientists/engineers you have within your entire network and the degree of connectivity between them.
A large group of experimentalists that are employed but are poorly connected will have a low ENV value, whilst the same team when highly connected will have a high ENV.
Djuli is designed to ensure the highest ENV for your R and D efforts.





djuli - Unlocking the Value of you Experimental Network
Djuli is a Cloud database from ZP designed to maximise the Experimental Network Value (ENV) of your experimental effort and make your experimental programme strong , rather than a source of frustration. Djuli does this by:
- Enforcing an experimental structure into your programmes.
- Ensuring that experimental results are reported in a consistent manner.
- Allowing the experimental reports to be easily searchable.
- Allowing real time visualization of experimental progress.
- Centralizing the storage of your experimental efforts.
- Ensuring the custodianship of your experimental data.
- Allowing experimental team that are geographical dispersed to work in the same place online.
- Sharing experimental data with internal and external stakeholders, through permissions settings.
- Allowing collaborating experimentalists to contribute directly into your programmes, including uploading into djuli.
- Avoiding the loss of experimental data within unstructured folder systems.
- A scalable system as djuli allows a new user to effortlessly set up an account, and then the Cluster owner can invite them to view, edit and contribute to the experimental effort.

Register and Login to Djuli
Welcome to the Djuli database.
Please click the image adjacent to register and login.

Djuli Learning Centre
You can explore our Djuli Learning Centre by clicking the button below.

DEFINTION OF ENV
The Experimental Network Value (ENV) is the value of your experimentalist network based on the number of experimentalists within your internal and external networks and is calculated based on the assumption that your scientists/engineers/experimentalists can see each other's experiments through a Cloud sharing system such as Djuli.
EXPERIMENTAL NETWORK VALUE OF ZERO

A single scientist working alone in a silo has an ENV of zero, as they are alone and outside of any networks. Even if there are other scientists in the programme a lack of coordination and collaboration will result in a collection of individuals with ENVs of zero.
EXPERIMENTAL NETWORK VALUE OF ONE

Two experimentalists on the same project and who are well coordinated and connected through djuli have an ENV of one.
EXPERIMENTAL NETWORK VALUE OF FIFTEEN

Six experimentalists that are fully connected through Djuli results in an experimental network with an ENV of fifteen, this reflects the non-linear growth of ENV as individuals are integrated into the Djuli platform,
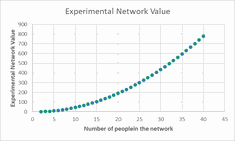
The Experimental Network Value (ENV,P) is a function of the number of experimentalists within your entire network and how well connected they are. The central function of the djuli database is to provide a centralised platform in the Cloud that all internal and external experimental resources can use to ensure a maximum value to your R and D effort expressed through the ENV value. The ENV for a well connected team of experimentalists increases non-linearly when collaborating through djuli.
Current Experimental Data Situation - The Worse Case Scenario
A common issue in many organizations is that individual experimentalists could be saving their data in different repositories or silos, or in the worst case on local computer drives, which are not backed up.
Though generic Cloud storage (One Drive, Google drive and Dropbox) seem like a solution these are not optimized for experimental lab data, and lab data can end up being distributed across files, folders and locked within personal folders.
Djuli ensures a centralized repository for your experimental data and effort, leaving it in a standardised, searchable and sharable format.


Structuring of Experimental Data
Djuli has a structure consisting of Cluster, Projects and Reports.
At the top level of the Djuli structure are Clusters, these are set up by the Senor Experimental Manager, and imposes the organization structure in which the experimentalists will build the content through their experimental efforts.
Under the Clusters are Projects. For example In the case of ZP we may have a Cluster called Fishtag and within the Cluster we have two Projects called Glucose and Cortisol. Under Projects in the Djuli architecture are Reports, this is where the experimentalist places details, data and information generated during an experiment. In the case of glucose sensor data this will go into the Glucose project as reports, whilst cortisol sensor data goes into the Cortisol Project as Cortisol Reports.


Searching through Experimental Data
An important feature of Djuli is that it ensures that experimental data is saved in one location and is searchable.
It is not uncommon that two years into a large programme that experiments can start to be repeated and so it is very important to know where the data is and to be able to search the historical record, both to remember and learn from the past and not to duplicate past efforts.
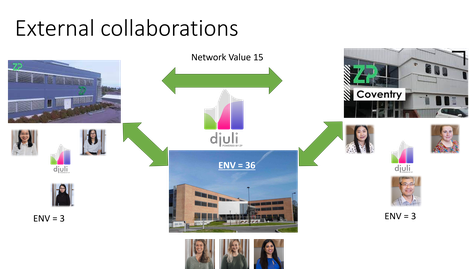
Sharing Experimental Data and Collaborations
Djuli is built on the tenet that experimental collaborations within teams and between teams are more powerful than experimentalists working alone or teams that are not efficiently connected.
A key feature of Djuli is the ability to increase the ENV of any experimental effort by using the permissions based sharing of data. By sharing data through Djuli with internal and external collaborators then the ENV of the programme increases.